We’re going to cover the common types of pagination in this tutorial including examples.
Before we jump ahead if you’re reading this an you’re already using SyncWith, keep reading to see how we enable you to handle pagination with any API
If you aren’t using SyncWith the tutorial will still be relevant as we review the different types BUT you might be interested in trying out our API connectors. SyncWith lets you:
Sync thousands of APIsdirectly to Google Sheets and Data Studio
- Keep
data synced on a schedule
Handles paginationautomatically for most popular APIs so you don’t have to or makes pagination easy if we don’t natively support it for the API
- Is priced very affordably with a free tier for hobbyists
TABLE OF CONTENTS
Lets Get Ready to use a Paginated APISupported request typesSupported pagination typesPage-based paginationOffset-based paginationCursor-based paginationURL-based paginationPagination parameters and JSON requestsResponsesRequestsTroubleshooting
Because some APIs limit the amount of data returned in each response for example (Google Ads will return a large response whereas Shopify will require you to paginate). To handle pagination you must make repeated calls to get each "page" of results, typically using page, offset, cursor or URL based pagination.
SyncWith can do this for you automatically for many popular styles of pagination and different kinds of requests.
Lets Get Ready to use a Paginated API
The first step in using a paginated API is recognizing that your API is paginated! Usually, you will notice that some data seems to be missing from your results. In its place, you will instead find a bit of JSON that hints at more data elsewhere. In this tutorial, we'll walk you through the most common cases.
Supported request types
SyncWith can paginate many kinds of HTTP requests:
- GET requests, where the parameters are passed in the query string, like https://example.com/api/endpoint?page=1
- POST requests with the
application/x-www-form-urlencodedcontent type, where the parameters are passed in the request body like page=1
- POST requests with the
application/jsoncontent type, where the parameters are passed in the request body as JSON object
- GraphQL POST requests, where the parameters are passed in the request's
variablessection
To learn more about paginating JSON based requests, please read Pagination parameters and JSON requests.
Supported pagination types
Page-based pagination
You can recognize a page-based API when:
• the response JSON has fields with names like
num_pages
• the API parameters have fields with names like pagePage-based pagination iterates through pages of fixed size starting from page 1, going to page 2, and so on until all pages are visited. Sometimes the page can start at 0.
ProPublica's Non-Profit API is an example of a page-based API. A search for all cat-focused non-profits returns this response, with 100 charities.
{ "total_results":110, "organizations":[ { ... kitten non-profit #1 ... }, ... { ... kitten non-profit #100 } ], "num_pages":2 }
But we can see that there are supposed to be 110 entries.
This response was retrieved from https://projects.propublica.org/nonprofits/api/v2/search.json?q=kitten&page=0
Let's configure pagination for this API:
page is the parameter that we'll change with each request. They start at 0. We'll stop when we've fetched as many pages as are specified in the num_pages field.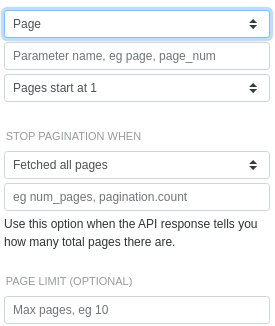
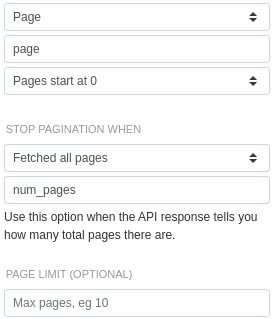
Offset-based pagination
You can recognize an offset-based API when:
• the response JSON has fields with names like
count, num_results or total_results
• the API parameters have fields with names like offset, skip or startOffset-based pagination is like page-based pagination, but a bit more flexible. Your request will specify how many results to skip and how many results to return. Because you are specifying how many results to skip, you usually start by skipping
0, i.e. you start at the start of the results.The CoinStats Coins API is an example of an offset-based API. Its responses look like:
{ "coins": [ { ... coin #1 ... }, ... { ... coin #1000 } ] }
This response was retrieved from https://api.coinstats.app/public/v1/coins?skip=0&limit=1000
To get the complete set of coins, we'll configure pagination for this API. We'll configure
limit in the typical way for parameters that don't change. offset is the parameter that we'll change with each request. It'll start at 0 and increment by 1000 on each call. Because this API doesn't tell us how many results there are, we'll configure SyncWith to stop when the coins field in the response is empty.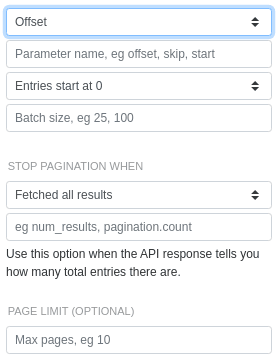
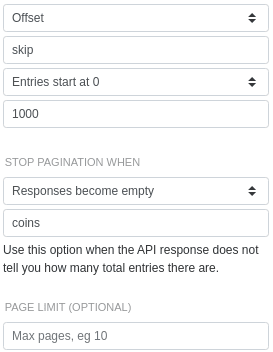
Cursor-based pagination
You can recognize a cursor-based API when its request parameters have names like
next or afterCursor-based pagination is like following a series of breadcrumbs. Each response will have a magic piece of information in it. You'll include this information in your next request to get the next set of results.
The Reddit API is an example of cursor-based pagination. Its responses look like:
{ "kind": "Listing", "data": { "after": "t3_hg8fae", "children": [ { ...post #1... }, ... { ...post #100... } ] } }
This response was retrieved from https://www.reddit.com/r/guernsey/.json
To get more than 100 posts, we'll configure cursor-based pagination.
after is the parameter that we'll change with each request. We'll get its value from the previous response's data.after field. Because this API can return many, many pages, we'll also stop iterating after the first 3 pages.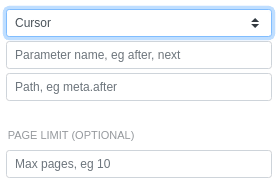
URL-based pagination
You can recognize a URL-based API when
• its HTTP response headers include the
Link header
• its response JSON has fields with names like next_url or next URL-based pagination is the batteries-included experience of pagination. Each response includes a fully-formed URL that will return the next set of responses.
Sometimes, this information is present in the
Link HTTP response header. The Shopify API is a popular example like this:Link: <https://example-store.myshopify.com/admin/api/2021-07/orders.json?limit=10&page_info=eyJsYXN0X2lkIjoyOTQ0NDgwMjQ3OTU5LCJsYXN0X3ZhbHVlIjoiMjAyMC0xMS0xMiAwMzoyNTo0OC4yNzIwOTEiLCJkaXJlY3Rpb24iOiJuZXh0In0>; rel="next"
More commonly, the information is present in the JSON response. The Cat Facts Breeds API has a response like this:
{ "current_page":1, "data": [ {...breed #1...}, ... {...breed #25...} ], "next_page_url":"https://catfact.ninja/breeds?page=2" }
This response was retrieved from https://catfact.ninja/breeds
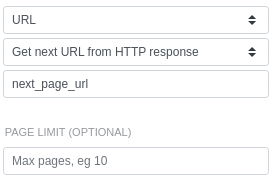
To get more than 25 breeds, we'll configure URL-based pagination. We'll tell SyncWith to use the
next_page_url field from the HTTP response:
Pagination parameters and JSON requests
Responses
SyncWith can extract pagination parameters from a JSON response body. For example, given a response like:
{ "responses": [ { "pagination": { "next_url": "https://example.com/api/endpoint/?page=2" } } ] }
You can tell SyncWith to find the next URL by configuring
responses.0.pagination.next_url as the source of the data. You specify the path by taking each element, in order, and separating them by periods. Note that arrays are indexed numerically, starting from zero.Requests
SyncWith can also send pagination parameters in JSON bodies. Specify a path using the same scheme as responses, and SyncWith will insert the parameter into that location.
This can be particularly useful for GraphQL requests. Consider this Shopify GraphQL request, which enumerates product variants:
query ($after: String) { productVariants(first: 10, after: $after) { edges { node { legacyResourceId } cursor } } }
It fetches the first 10 variants, starting from the
after variable.A response looks similar to:
{ "data": { "productVariants": { "edges": [ { "node": { "legacyResourceId": "40204185272515" }, "cursor": "eyJsYXN0X2lkIjo0MDIwNDE4NTI3MjUxNSwibGFzdF92YWx1ZSI6IjQwMjA0MTg1MjcyNTE1In0=" }, // ... 8 more entries { "node": { "legacyResourceId": "40204186321091" }, "cursor": "eyJsYXN0X2lkIjo0MDIwNDE4NjMyMTA5MSwibGFzdF92YWx1ZSI6IjQwMjA0MTg2MzIxMDkxIn0=" } ] } } }
To paginate this request, we need to extract the correct
cursor value from this response and send it as a variable in the next request. This is possible with these pagination settings:- Pagination type:
Cursor
- Parameter name:
variables.after - This tells SyncWith to update the JSON object in the request to include a
variableskey that has anafterkey
- Path:
data.productVariants.edges.9.cursor - This tells SyncWith where to find the value from the
afterkey. We want to continue requesting data, starting just after the last item we retrieved. Because we requested 10 items, and because arrays start at 0, the correct path needs to use9
Troubleshooting
If you can't get your API to work, try Googling for information. For example, to learn how Shopify paginates its responses, you might try searching for
shopify pagination api. If you're stuck, send us an email at hello@syncwith.com and we'll see if we help get you unblocked!